
dbt™ Labs helps data teams work like software engineers—to ship trusted data, faster.
dbt(data build tool) is a data transformation framework that makes building and deploying data models easy. This is done by introducing software engineering best practices like modularity, testability, CI/CD, and documentation.
In practice dbt lets you create data models with pure SQL select statements. These models are then converted into tables and views when you run dbt. There is no need to write create table statements, store procedures, etc. as dbt handles all the DDL/DML. This means that the barrier to entering the data warehouse becomes much more accessible.
In addition, this lets dbt store all the select statements as code in a git repository. You can version your data much more like code, hence enabling easy collaboration. Combine this with dbt easy way to set up tests on your data, you can create very elegant CI/CD pipelines that you can define with confidence.
Extra juicy benefits of dbt Labs
dbt is a layer on top of your data warehouse and it is created such that it can work on different backends. This means that you can use dbt via the officially supported connectors for Snowflake, Databricks, or Redshift, or even community-supported connectors for Azure SQL or ClickHouse.
The core version of dbt is open source and anyone can look and contribute to the code in dbt. This means that if you really want a feature, you can develop it and have an incentive to do so. This leads to a large and friendly community around dbt, which can be found on Slack. In addition, more eyes on the code often mean better code.
What makes dbt Labs unique?
What makes dbt Labs unique?
“I love how dbt Labs just lets me focus on creating data models instead of moving data around. I really like how easy it is to set up tests on your data with dbt. It is fast to set up tests on all your columns like not null, unique, or has relation. In addition, you can create custom tests that fit your business logic. This makes your transformations much safer.
dbt Labs Community
Also, I am down with the community around dbt. I can almost find everything on the slack channel and the way that you can develop and use other packages for dbt is awesome.”
dbt Labs Best Practices
“The way we have been working with modeling data in data warehousing has not changed much over the last 10 years. dbt, bring the software engineering best practices that have been missing big time all these years.
Our partnership with dbt, not only shows what we think is the right way of working with data but also shows our dedication to the open-source community behind this great technology.
Highly Skilled in dbt Labs
At the moment several people in Intellishore are already highly skilled in dbt that is also shown by all the dbt certificates. We have also contributed to a new add-on to the open-source community.
Jonatan Larsen Edry
Senior Consultant at Intellishore
You'll see how this transformative technology can help you deliver value and success to your organization.
We will also provide you with some more inspiration on how you can unlock more value to your organization by utilizing dbt Labs.
We look forward to hearing from you.
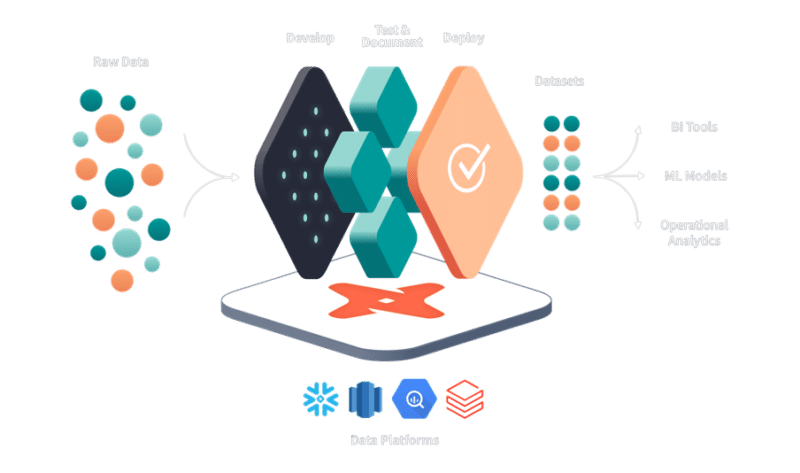
How dbt Labs works
How dbt Labs works
dbt Labs: Version Control and CI/CD
Deploy safely using dev environments. Git-enabled version control enables collaboration and a return to previous states.
Test and Document
Test every model prior to production, and share dynamically generated documentation with all data stakeholders.
Develop
Write modular SQL models with SELECT statements and the ref() function– dbt handles the chore of dependency management.
You can learn more from dbt Labs’ Success Stories here.

The mission of dbt Labs - Enabling best practice
The mission of dbt Labs - Enabling best practice
“For several years, we at dbt Labs have been on a mission to help analysts create and disseminate organizational knowledge, and I believe this vision very much aligns with Intellishore’s.
dbt Labs Enables Data Transformation
dbt enables data teams to transform their data in-warehouse and deploy analytics code following software engineering best practices. This new way of working, known as analytics engineering, was pioneered by dbt Labs and we have been fortunate enough to see a fantastic community coalesce to help push its boundaries.
What makes dbt Labs stand out?
What makes dbt different from other ways of managing data? The idea is that analytics should be collaborative. With dbt, anyone in an organization who knows how to write basic SQL can contribute to transformation pipelines, from source data to data models ready for consumption.
While we are expanding access, we also need to ensure that data teams are working in a way that is secure, governed, tested, and easily understood. dbt integrates with git, tests data before changes are pushed into production, and automatically documents the data with descriptions and out-of-the-box lineage graphs, so it’s easy to understand the source and dependencies of every data model.
Intellishore; An Expert dbt Labs Implementation Partner
And having expert implementation partners like the team at Intellishore helps our customers get the most value out of a tool like dbt. We’re grateful to be partnering with them. Intellishore has been a tremendously valuable partner in helping us advance the practice of analytics engineering.”

Five reasons why dbt sets a new standard for data transformation
Develop faster
Replace boilerplate DDL/DML with simple SQL SELECT statements that infer dependencies, build tables and views, and run models in order. Write code that writes itself with macros, ref statements, and auto-complete commands in the Cloud IDE.
Work from the same assumptions
dbt’s pre-packaged and custom testing helps developers create a “paper-trail” of validated assumptions for data collaborators. Auto-generated dependency graphs and dynamic data dictionaries promote trust and transparency for data consumers.
Deploy with confidence
Build observability into transformation workflows with in-app scheduling, logging, and alerting. Protection policies on branches ensure data moves through governed processes including dev, stage, and prod environments generated by every CI run.
Governance
Eliminate data doubt with version control, testing, logging, and alerting. Snapshot changes over time and provides open access to hosted documentation.
Security
Manage risk with SOC-2 compliance, CI/CD deployment, RBAC, and ELT architecture.